Introduction
Have you ever wished you could bring a character from a photo or drawing to life? Well now you can with Animate Anyone, an exciting new image-to-video generation method created by researchers at Alibaba.
What is Animate Anyone?
Animate Anyone is a framework that can transform a still image of a character into a realistic, moving video controlled by a sequence of poses. Some key things it can do:
- Animate a wide variety of characters including humans, cartoons, animals, etc.
- Generate sharp, detailed videos that closely match the appearance of the input image
- Produce smooth, natural motions between frames without jitter or flickering
- Allow control over the character’s movement through pose sequences
The method utilizes recent advances in diffusion models, a type of deep learning technique that has shown impressive results for image and video generation. Specifically, Animate Anyone builds on top of Stable Diffusion with several custom components tailored for consistent and controllable character animation.
How Does It Work?
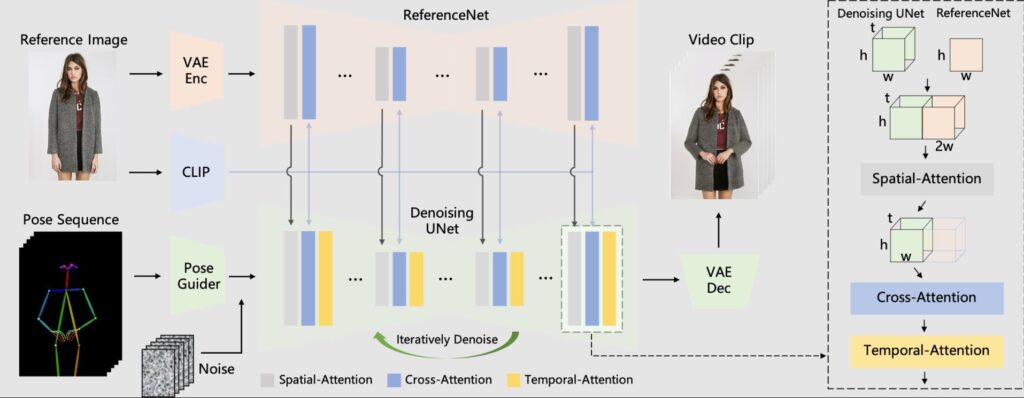
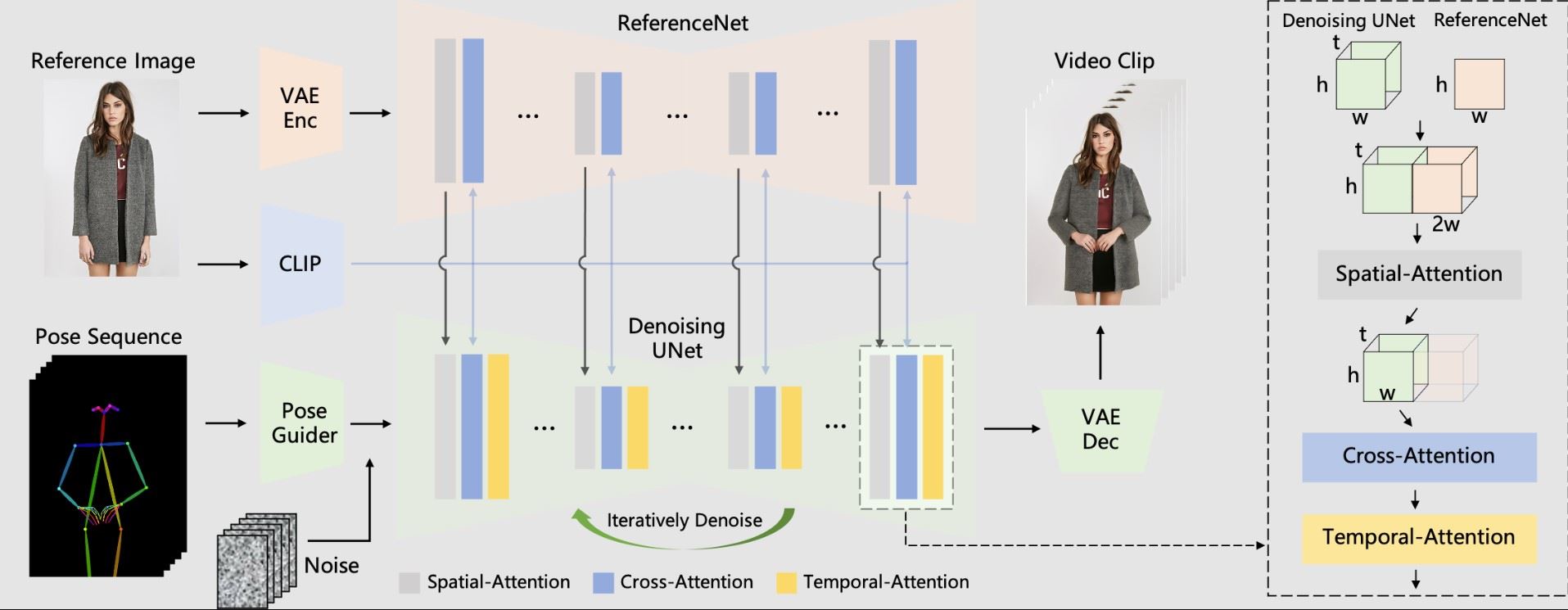
The Animate Anyone framework takes two inputs:
- A reference image showing the character to be animated
- A sequence of pose skeleton images indicating desired motions
It then goes through the following steps to generate a video:
- Encode appearance details from the reference image using a custom ReferenceNet. This preserves fine details like clothing textures.
- Encode pose sequences with a lightweight Pose Guider module to enable control over motions.
- Pass inputs into a diffusion-based denoising process to predict video frames that match poses while maintaining detail consistency.
- Employ temporal modeling to ensure smooth transitions between frames.
Let’s break down some of these key components:
ReferenceNet
This custom subnet accurately captures intricate details from the reference image like clothing prints or wrinkles. It provides these spatially-aligned details to the main diffusion network during video generation so output frames remain consistent.
Pose Guider
This module encodes the pose sequence images into control signals that direct the character’s movement. This enables easy control during animation.
Diffusion Process
The core of animation happens through an iterative denoising process modeled after Stable Diffusion. This predicts video frames that match the encoded pose signals while referencing details from ReferenceNet for fidelity to the original image.
Temporal Modeling
Additional temporal layers ensure smooth motion and prevent jitter between frames. This leads to nice continuity in the final videos.
Results
The researchers demonstrate Animate Anyone on a variety characters from full human bodies to anime portraits with impressive results:
- Lifelike, high-quality videos
- Consistent details matching input images
- Controlled motion following pose cues
- Smooth transitions between frames
The method also outperforms prior state-of-the-art solutions on specialized benchmarks for fashion video synthesis and human dance generation.
Some limitations still exist around stability of fine details during complex motions, but outcomes clearly set a new bar for controllable image-to-video generation.
Applications
There are many potential applications for this technology:
- Generate custom avatars from profile pictures
- Animate characters for films or video games
- Create virtual try-on videos for online fashion retail
- Produce marketing videos for products with characters
- Assist digital artists and animators with preliminary motions
Availability
While Animate Anyone shows promising animation capabilities, the technology remains in early research stages without an official product release. Alibaba needs to continue testing and refining the system before considering public launch. As with many cutting edge AI innovations translating academic research into real-world applications comes with hurdles around infrastructure, productization and regulating synthetic media usages. Despite state-of-the-art performance, robustness across diverse datasets requires validation too. With such potential impacts, Alibaba has incentives to keep developing Animate Anyone into dependable consumer accessibility, but typical enterprise cycles here span 1-2 years minimum.
Unless roadblocks emerge, excited users could hope to hear about beta access or licensing options by 2024 or 2025. For now animation fans simply need some patience; bringing personal images to life with Animate Anyone will come in due time.
Read Also : Leonardo AI Live Canvas – A Guide for Newbies
Conclusion
As the quality and capabilities continue to improve, Animate Anyone could provide a foundation for easily bringing still images to life in various industries.
The future looks bright for this new avenue of generative media! Diffusion models paired with clever techniques open possibilities to animate the world around us.